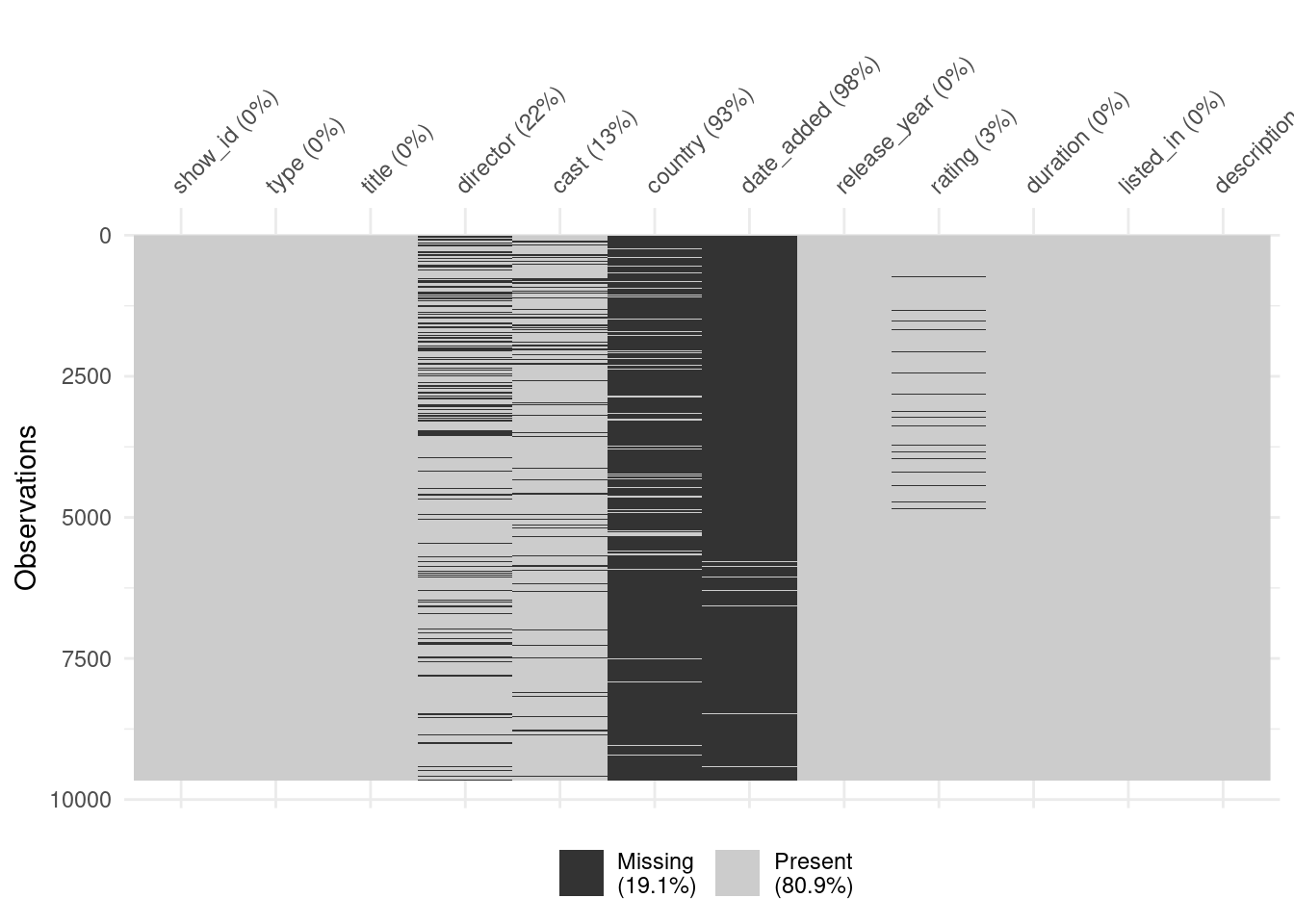
Rows: 9,668
Columns: 12
$ show_id <chr> "s1", "s2", "s3", "s4", "s5", "s6", "s7", "s8", "s9", "s1…
$ type <chr> "Movie", "Movie", "Movie", "Movie", "Movie", "Movie", "Mo…
$ title <chr> "The Grand Seduction", "Take Care Good Night", "Secrets o…
$ director <chr> "Don McKellar", "Girish Joshi", "Josh Webber", "Sonia And…
$ cast <chr> "Brendan Gleeson, Taylor Kitsch, Gordon Pinsent", "Mahesh…
$ country <chr> "Canada", "India", "United States", "United States", "Uni…
$ date_added <chr> "March 30, 2021", "March 30, 2021", "March 30, 2021", "Ma…
$ release_year <dbl> 2014, 2018, 2017, 2014, 1989, 1989, 2017, 2016, 2017, 199…
$ rating <chr> NA, "13+", NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
$ duration <chr> "113 min", "110 min", "74 min", "69 min", "45 min", "52 m…
$ listed_in <chr> "Comedy, Drama", "Drama, International", "Action, Drama, …
$ description <chr> "A small fishing village must procure a local doctor to s…
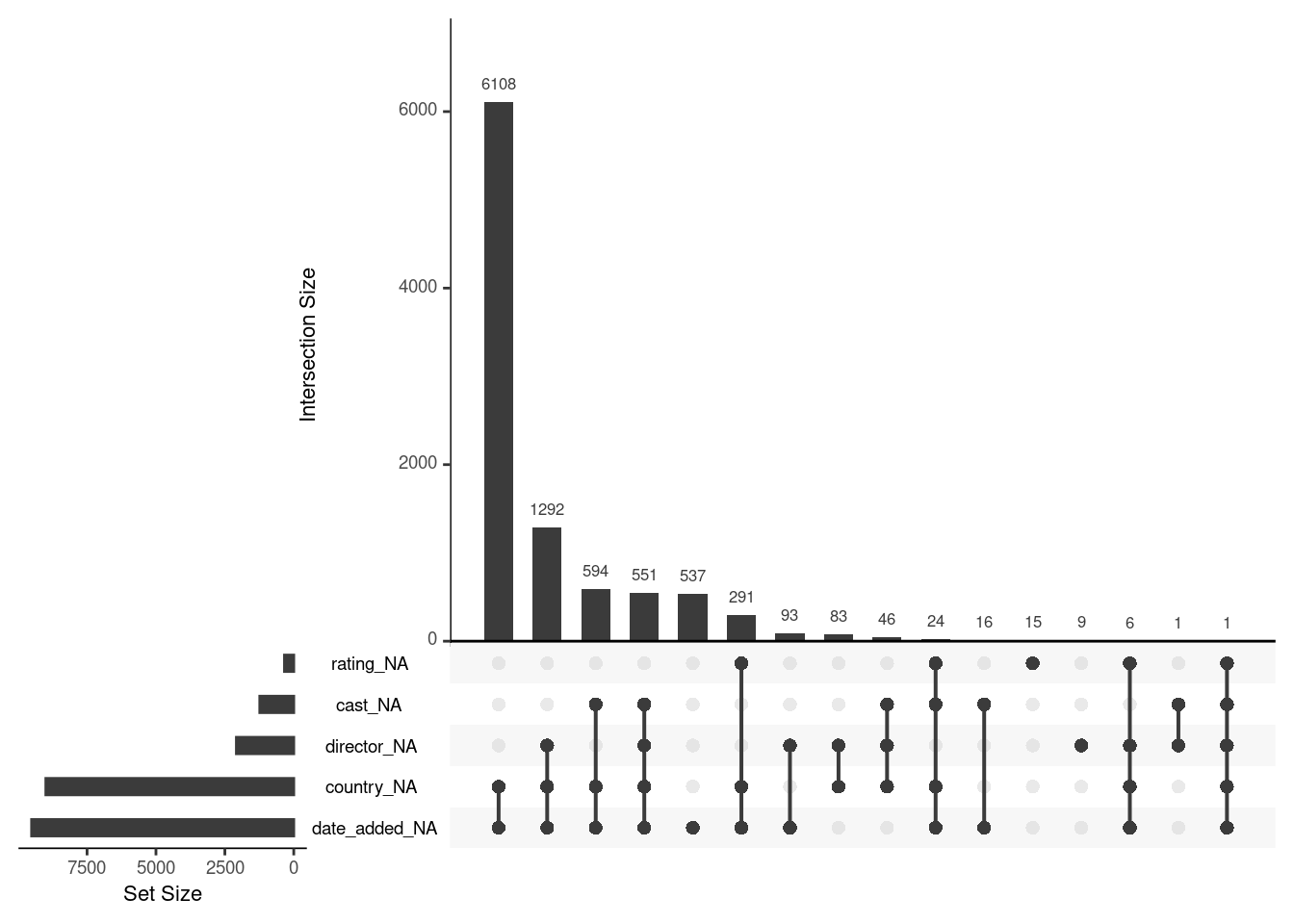
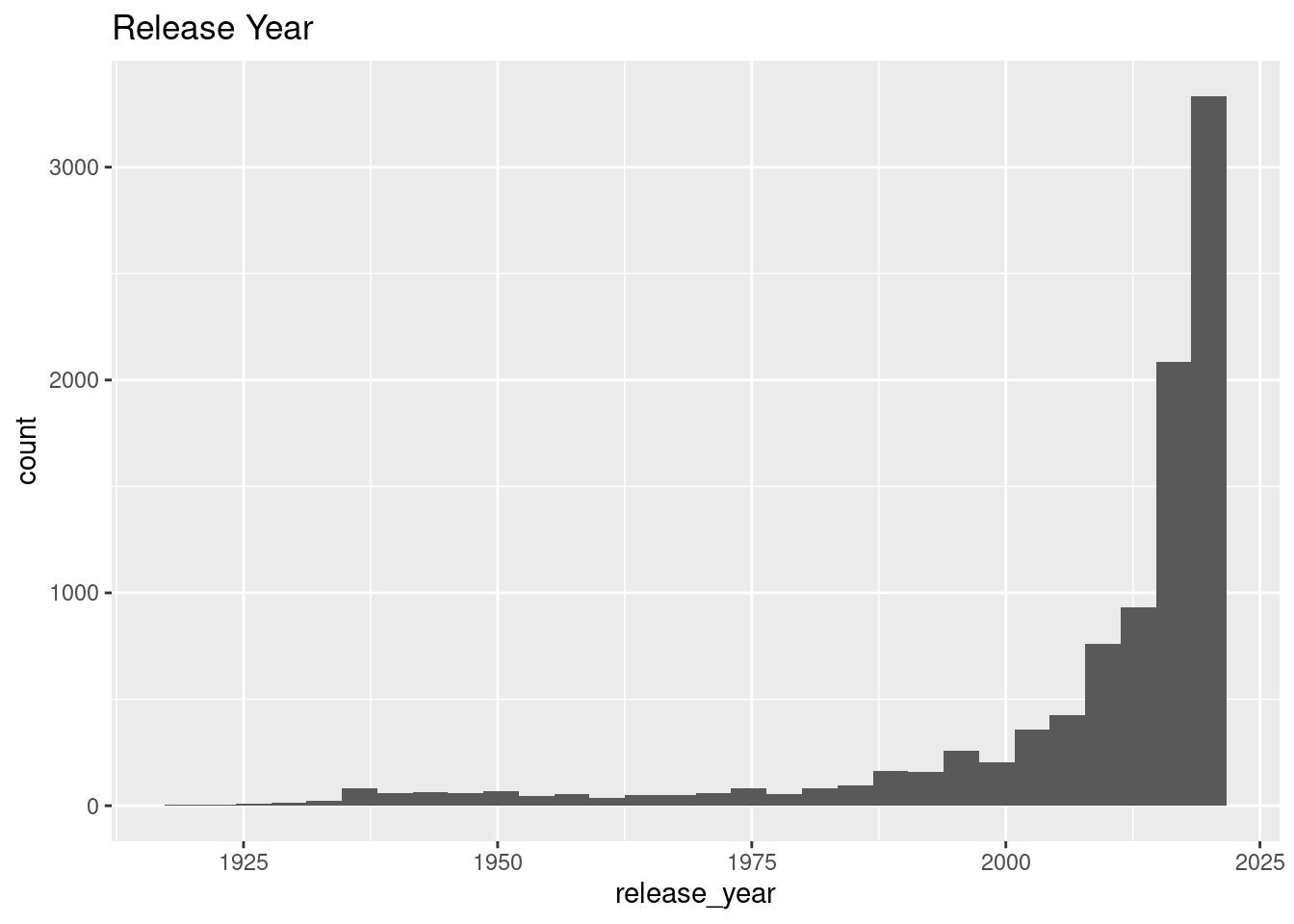
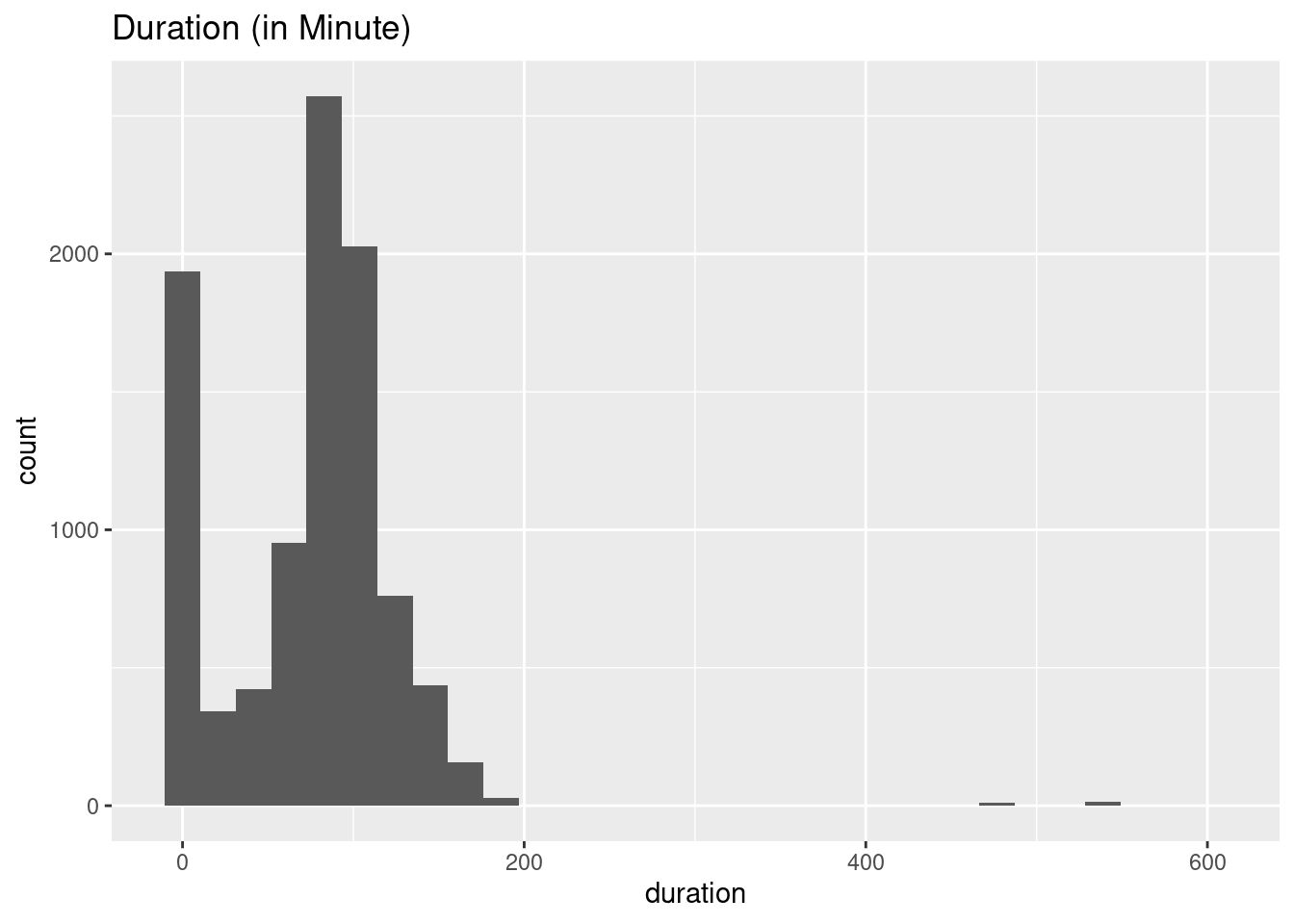
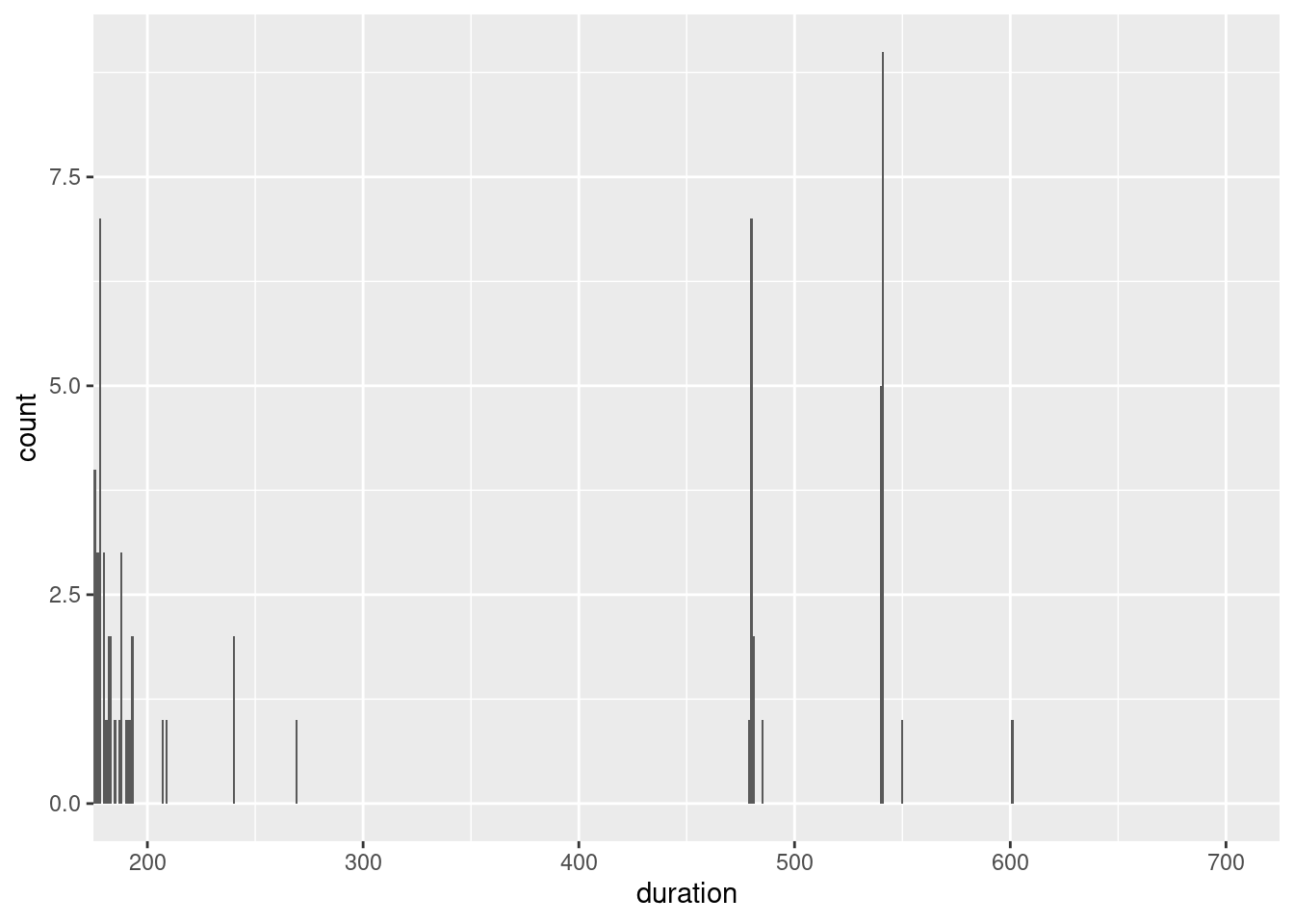
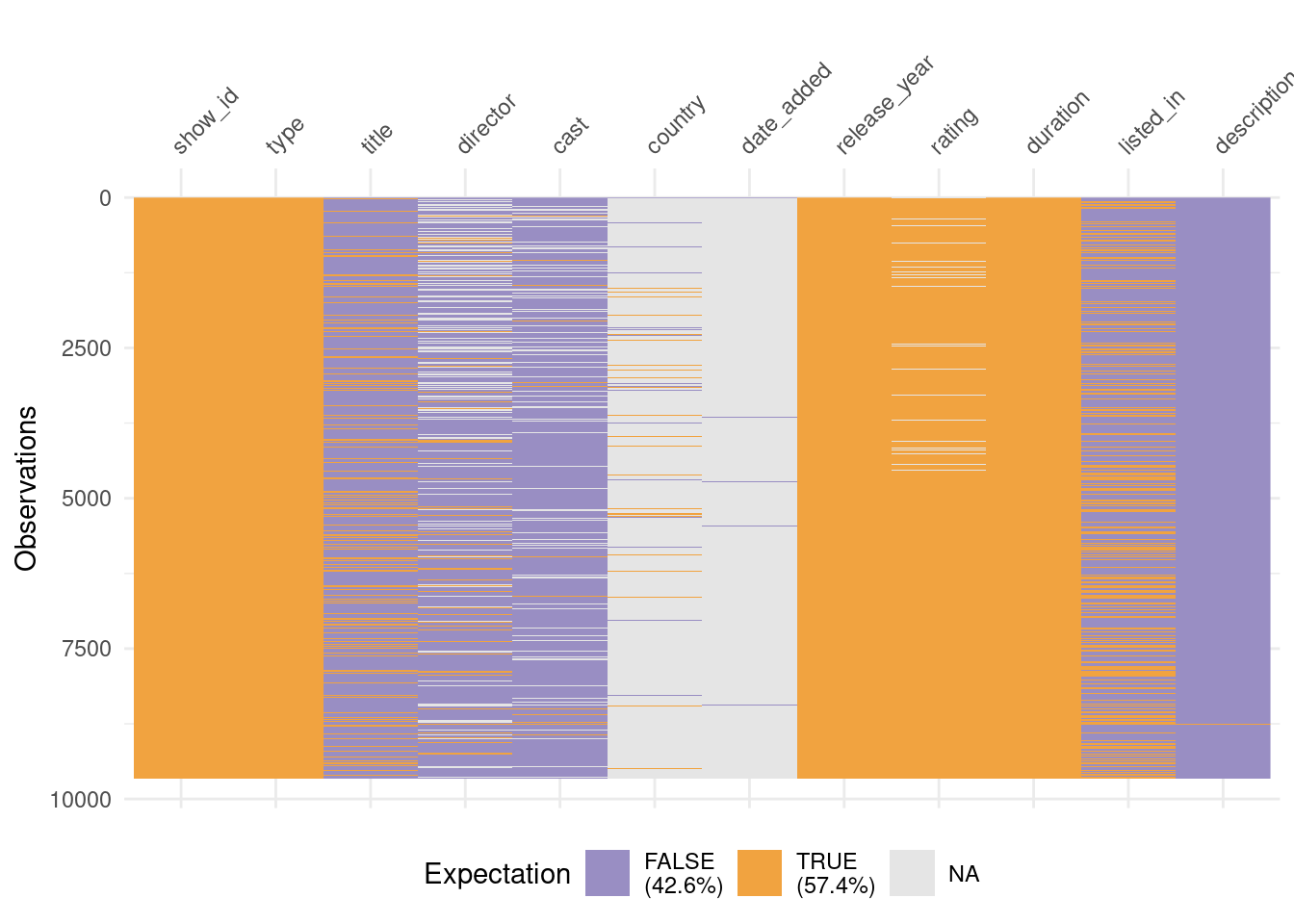

 Source:
Source: