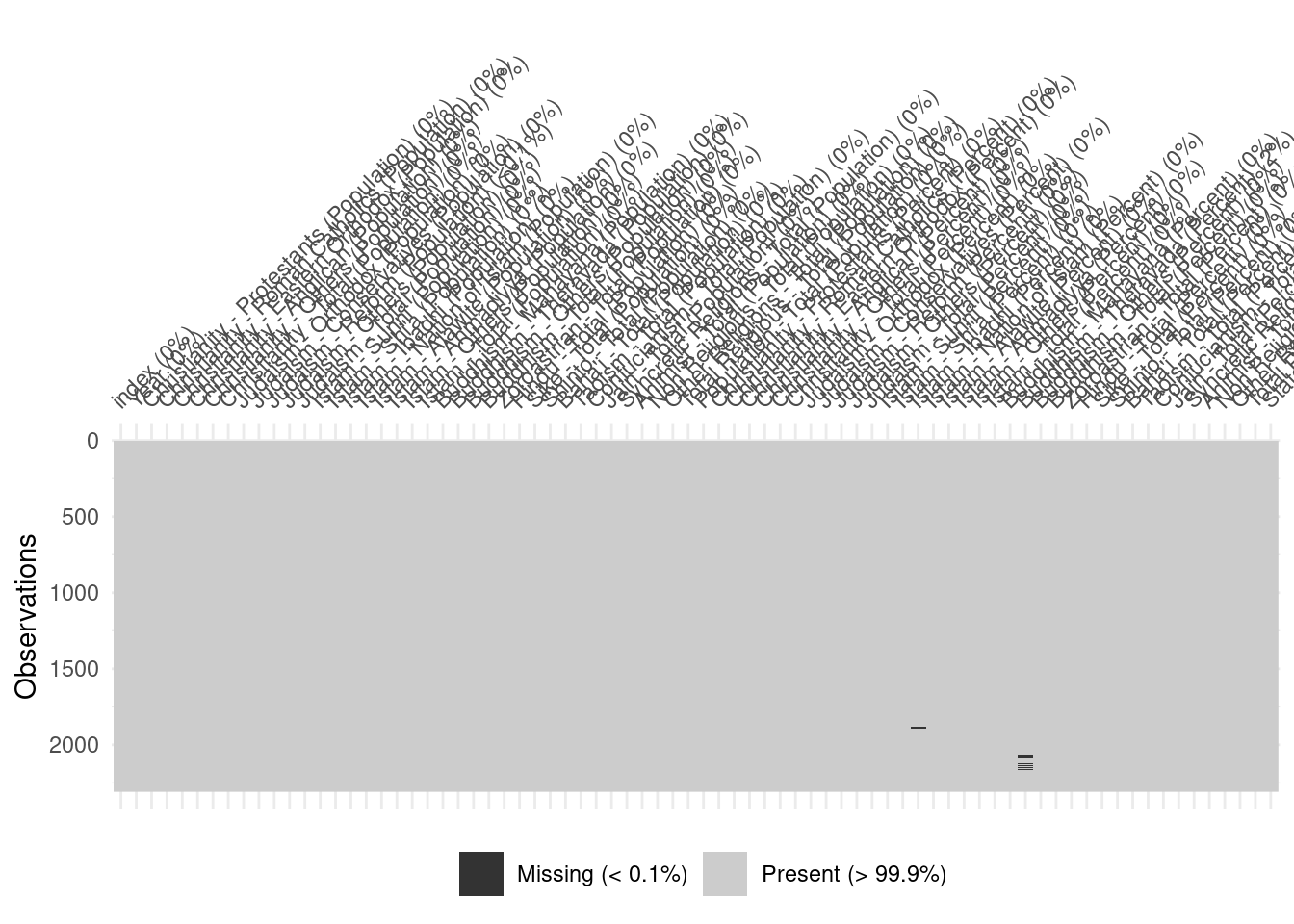
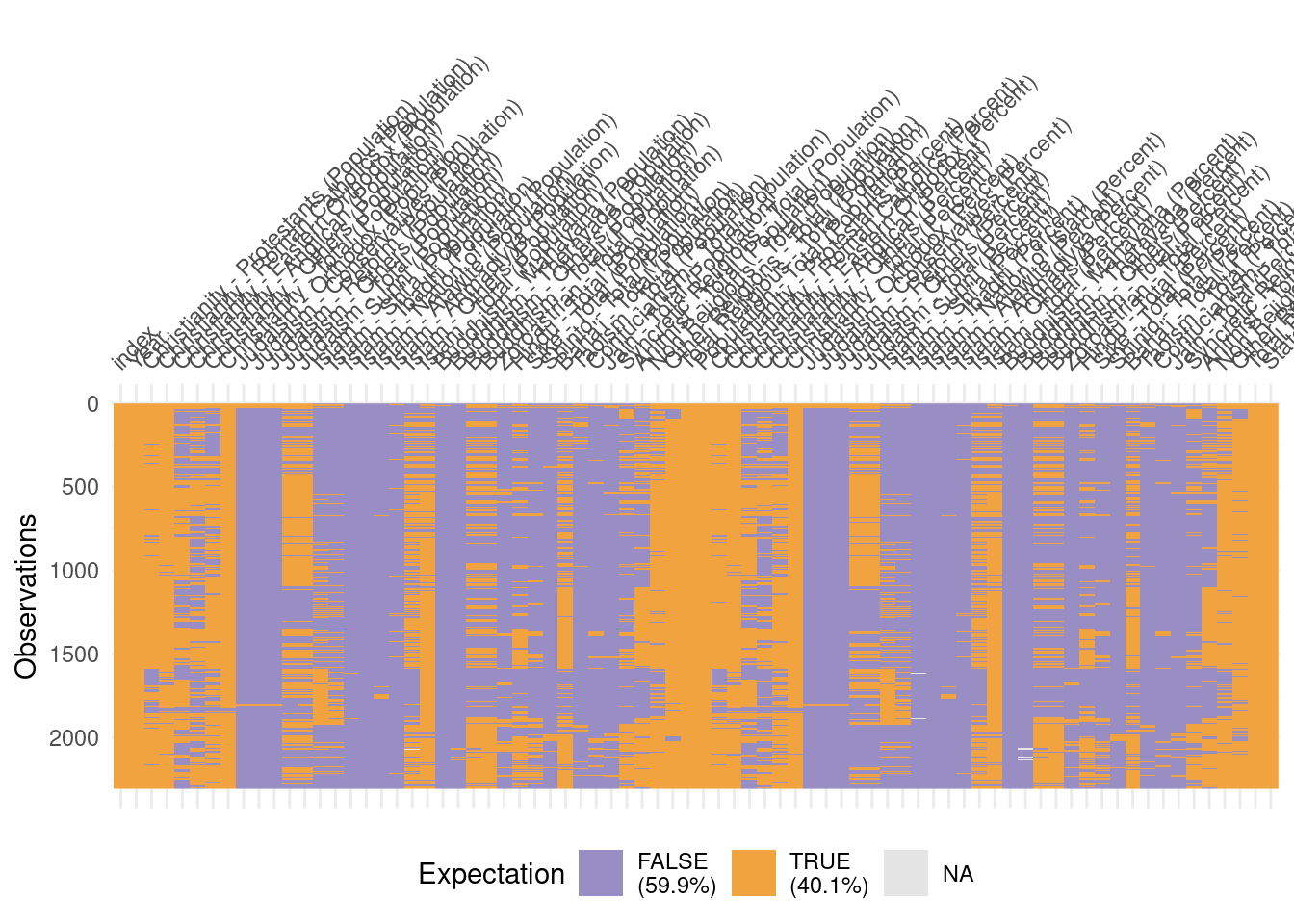
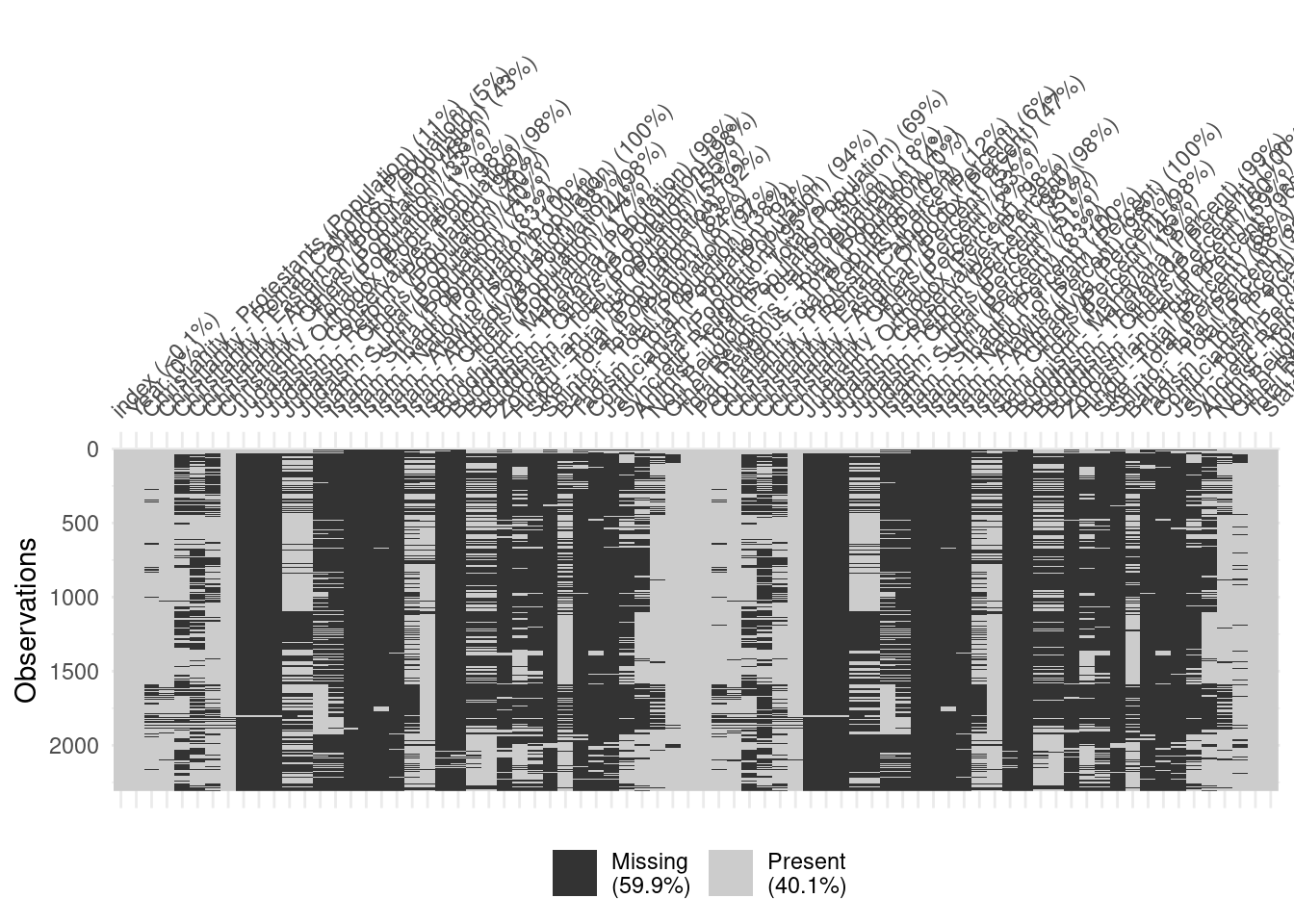
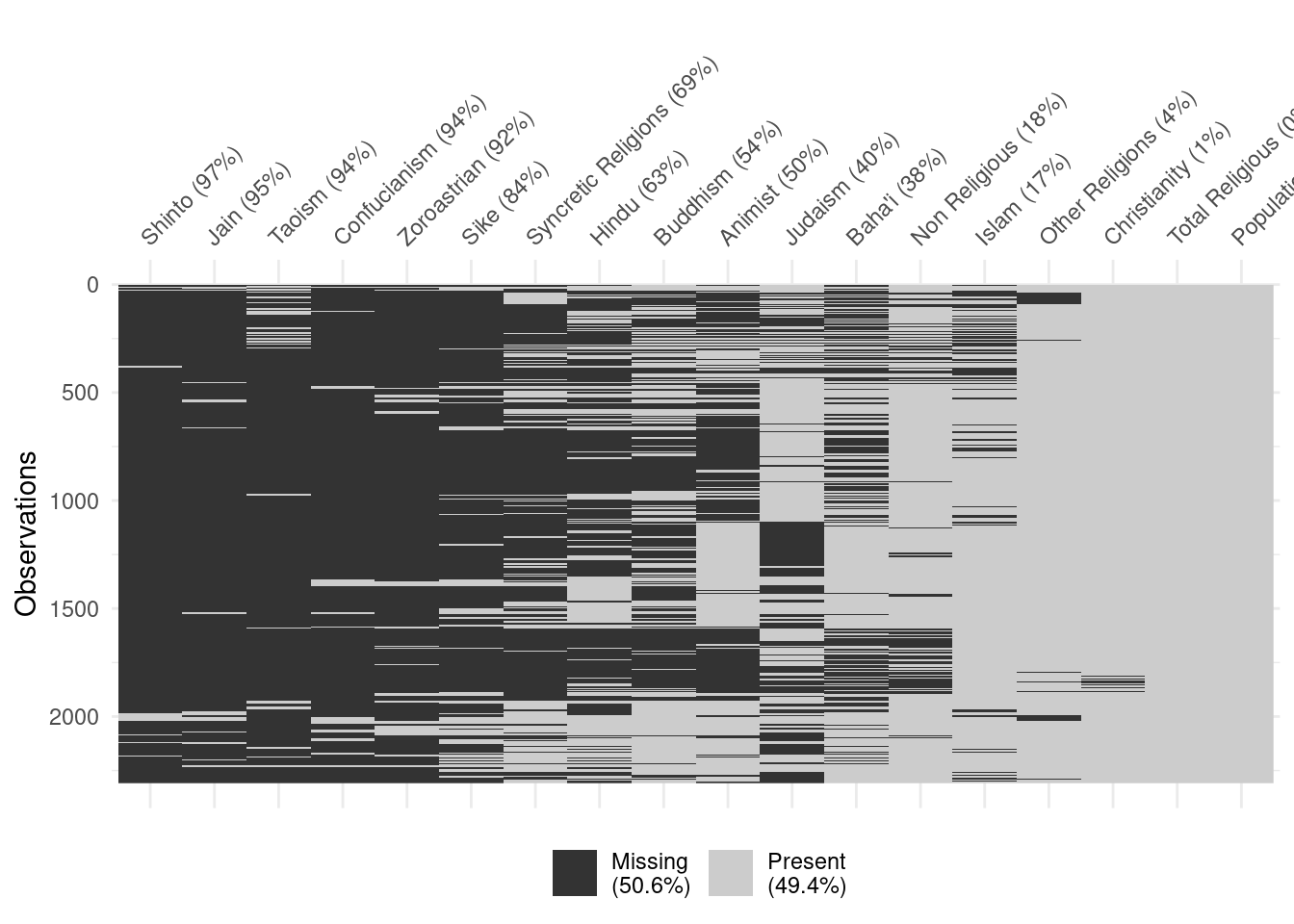
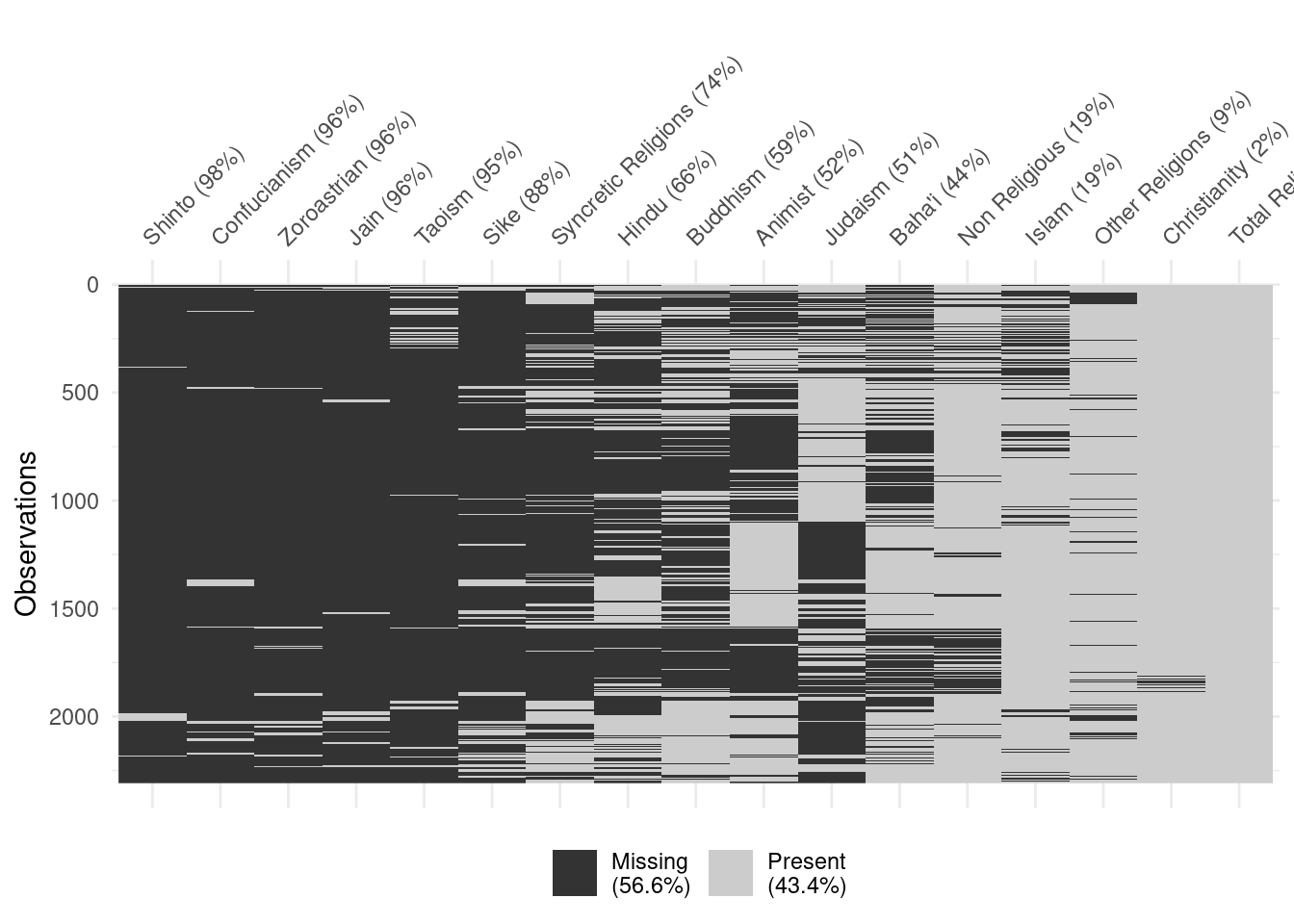
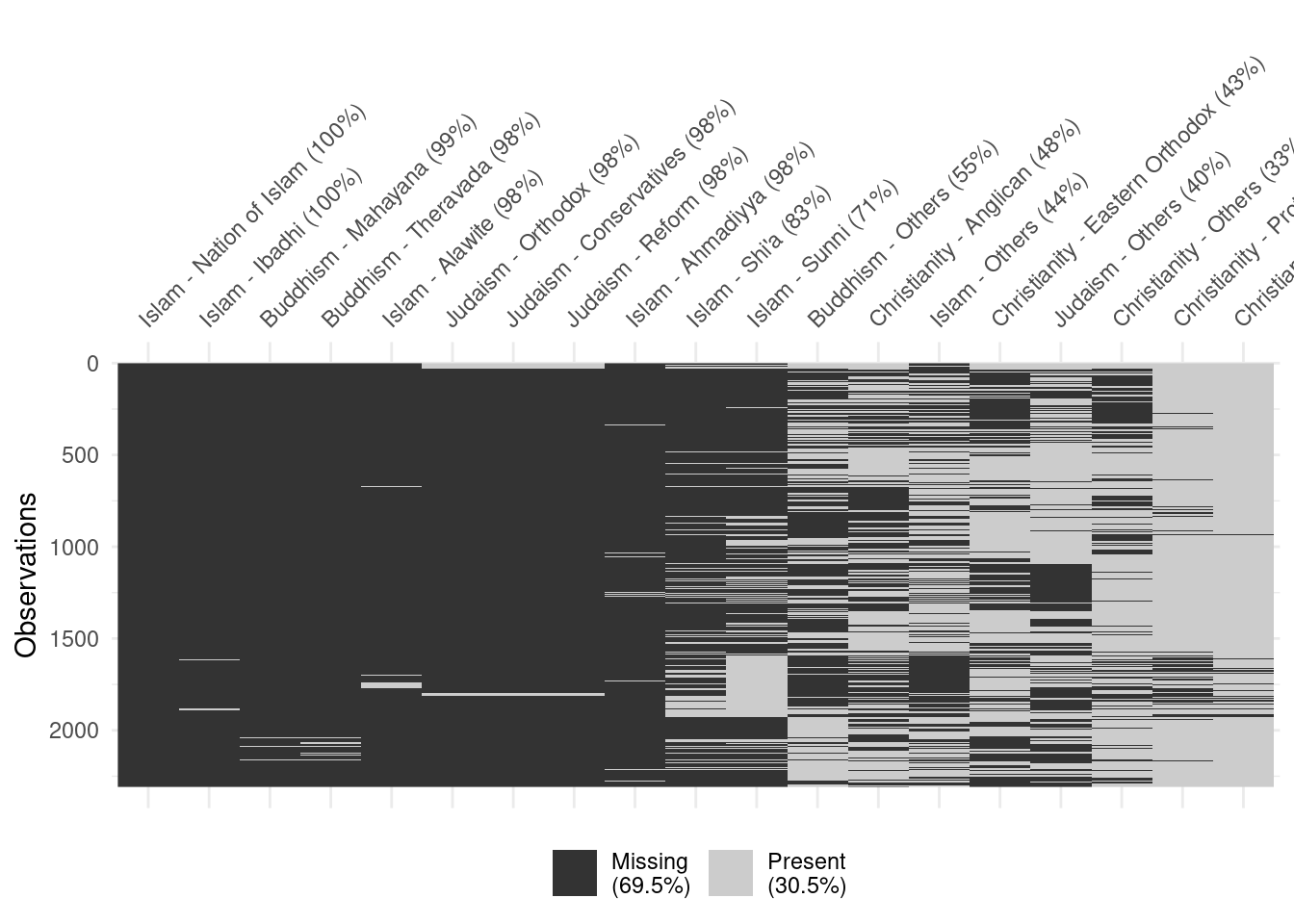
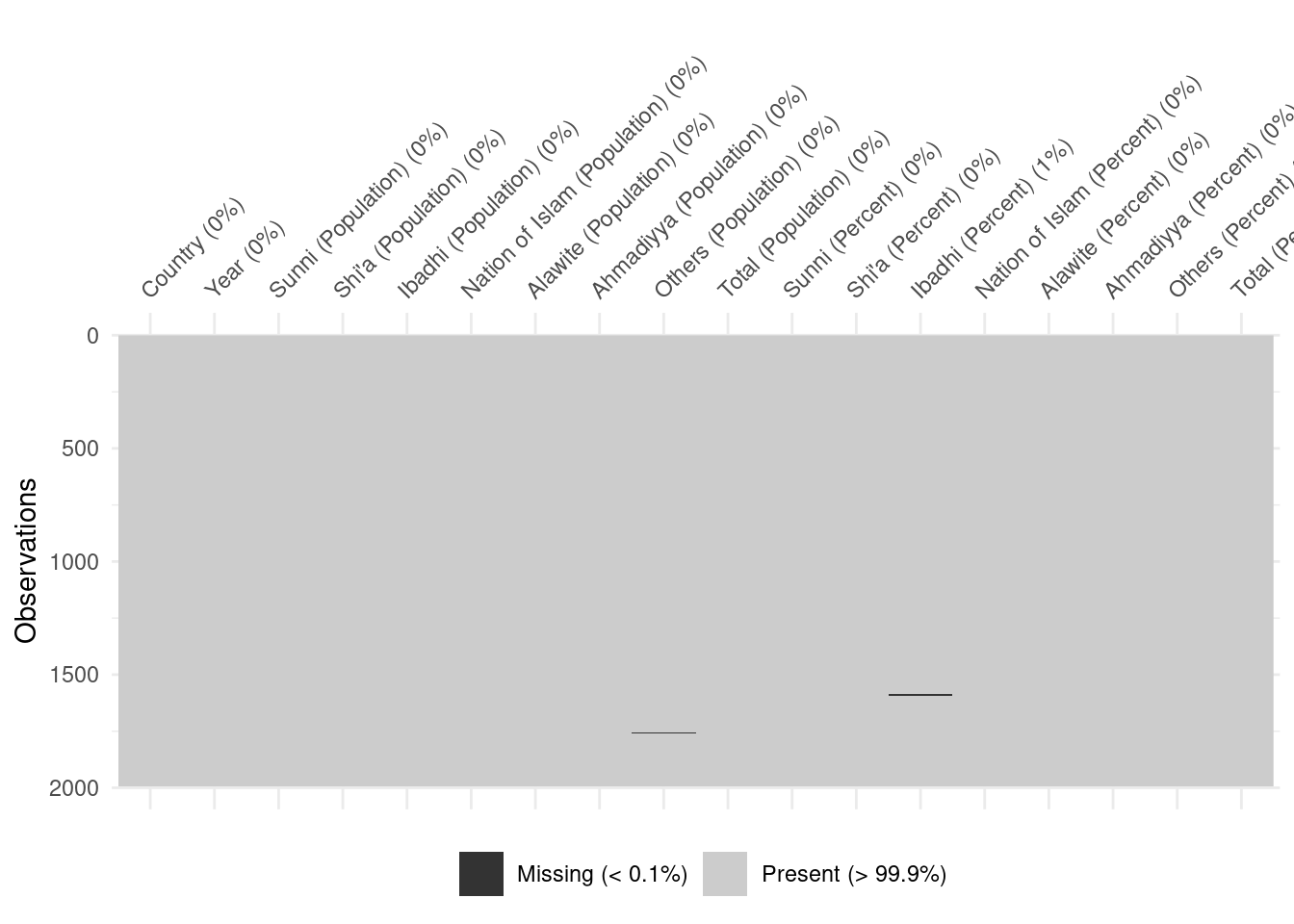
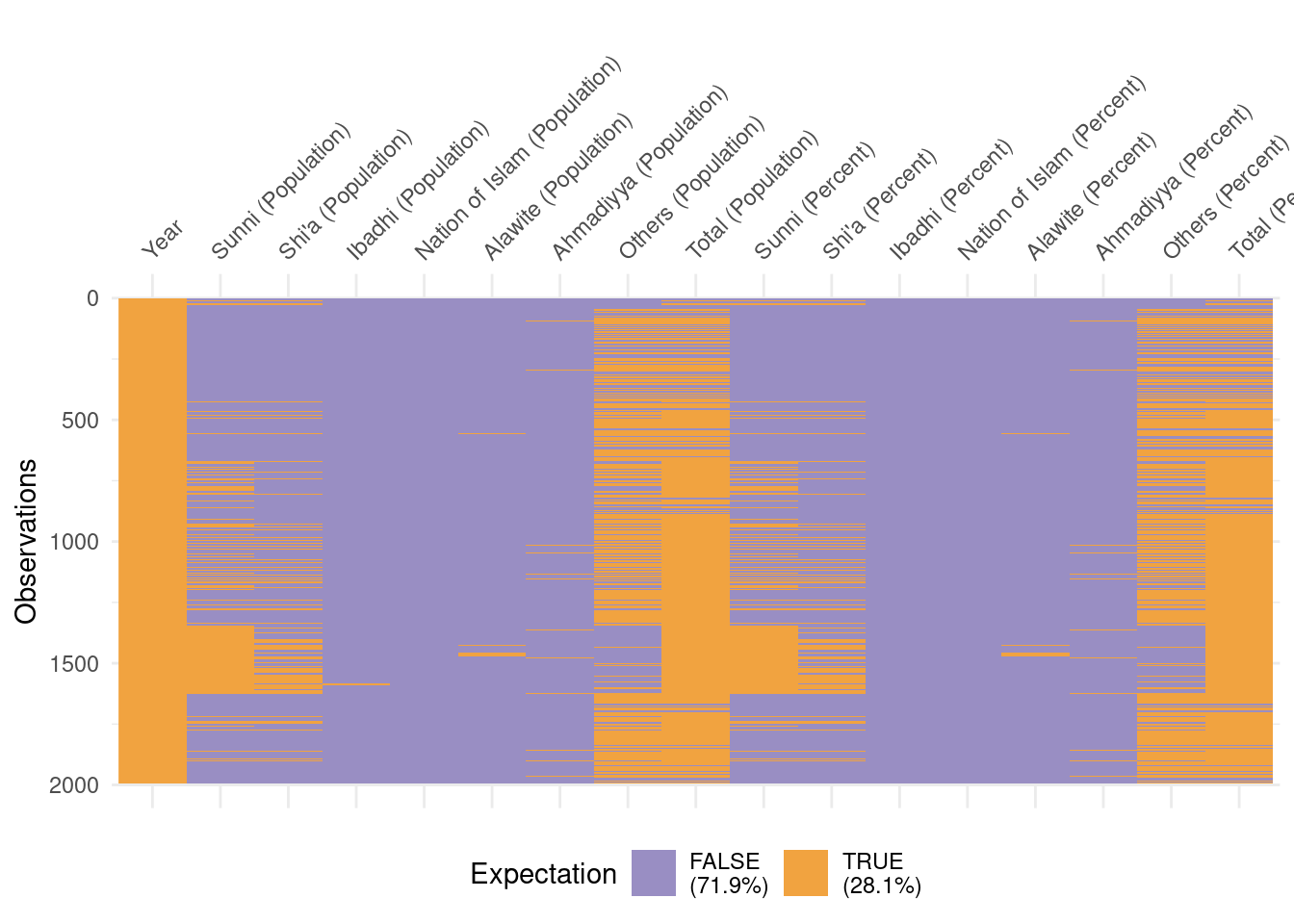
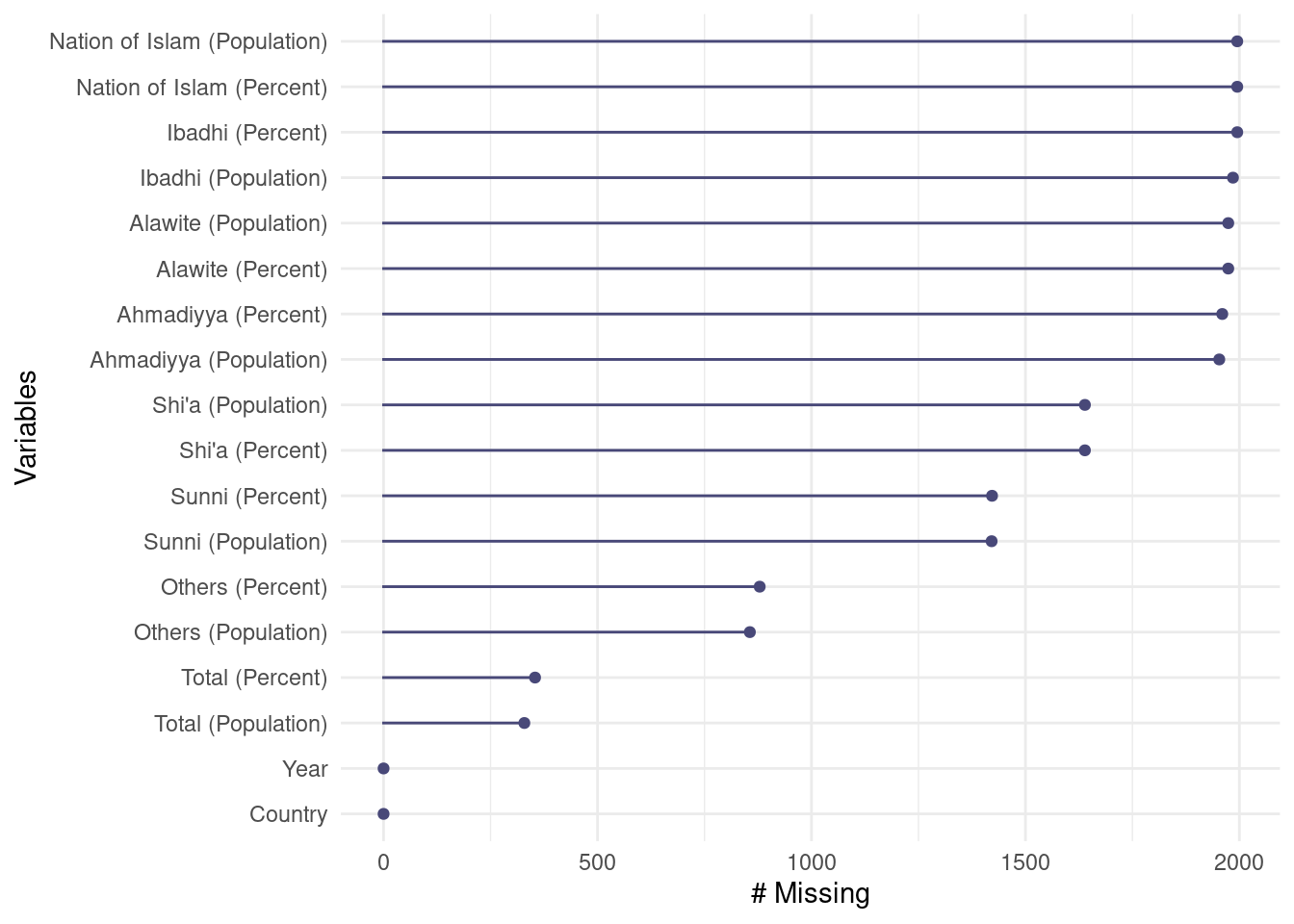
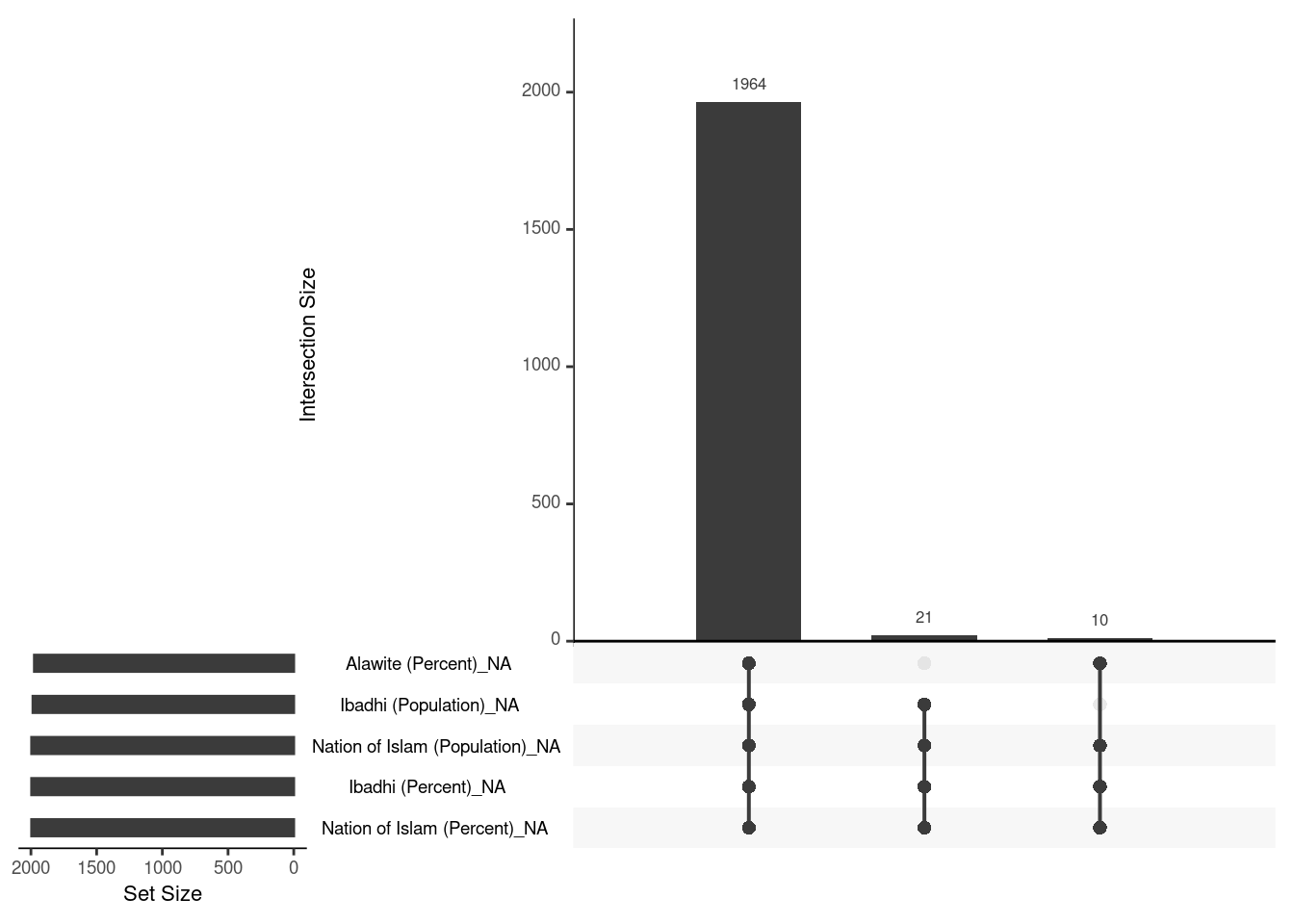
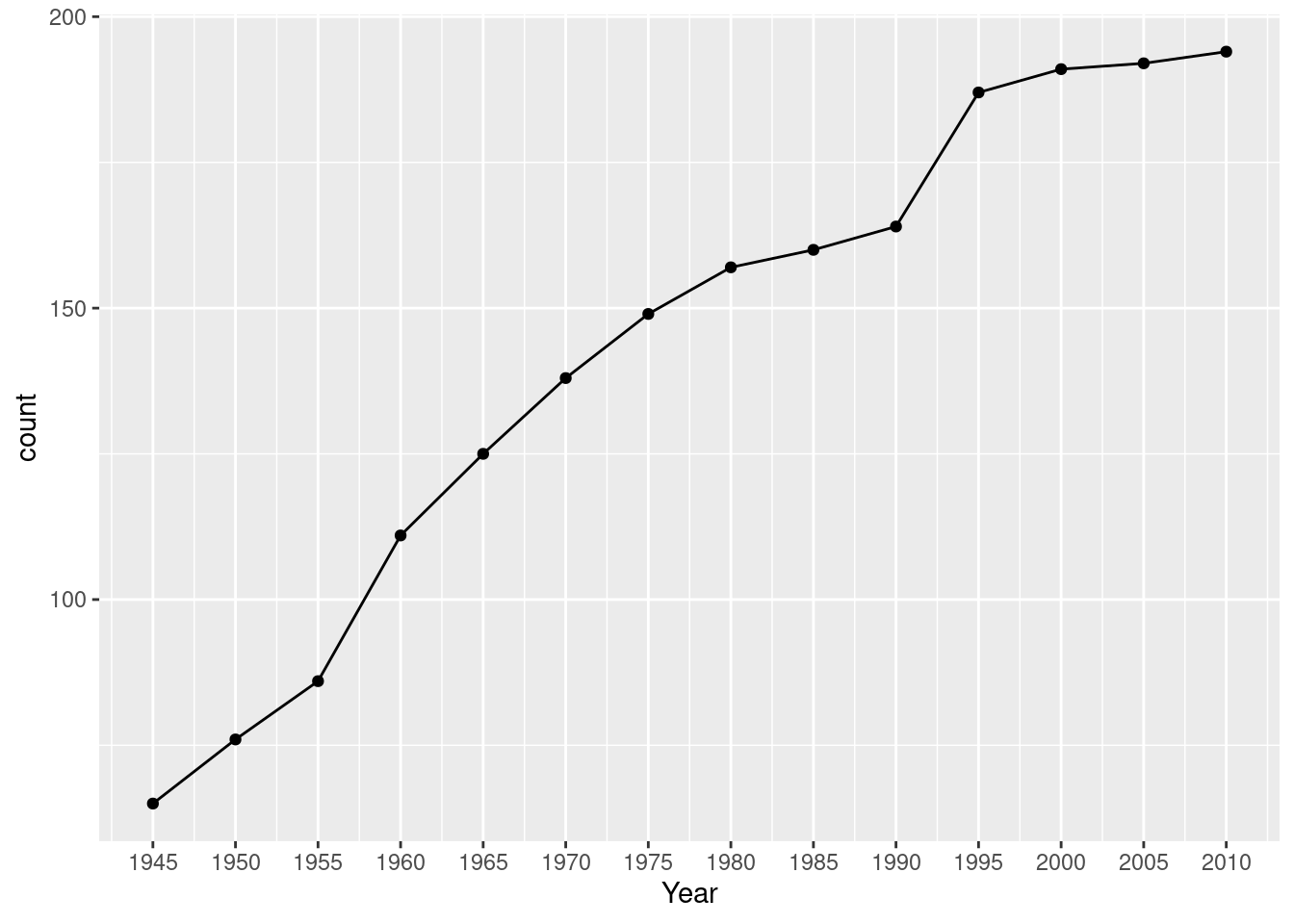
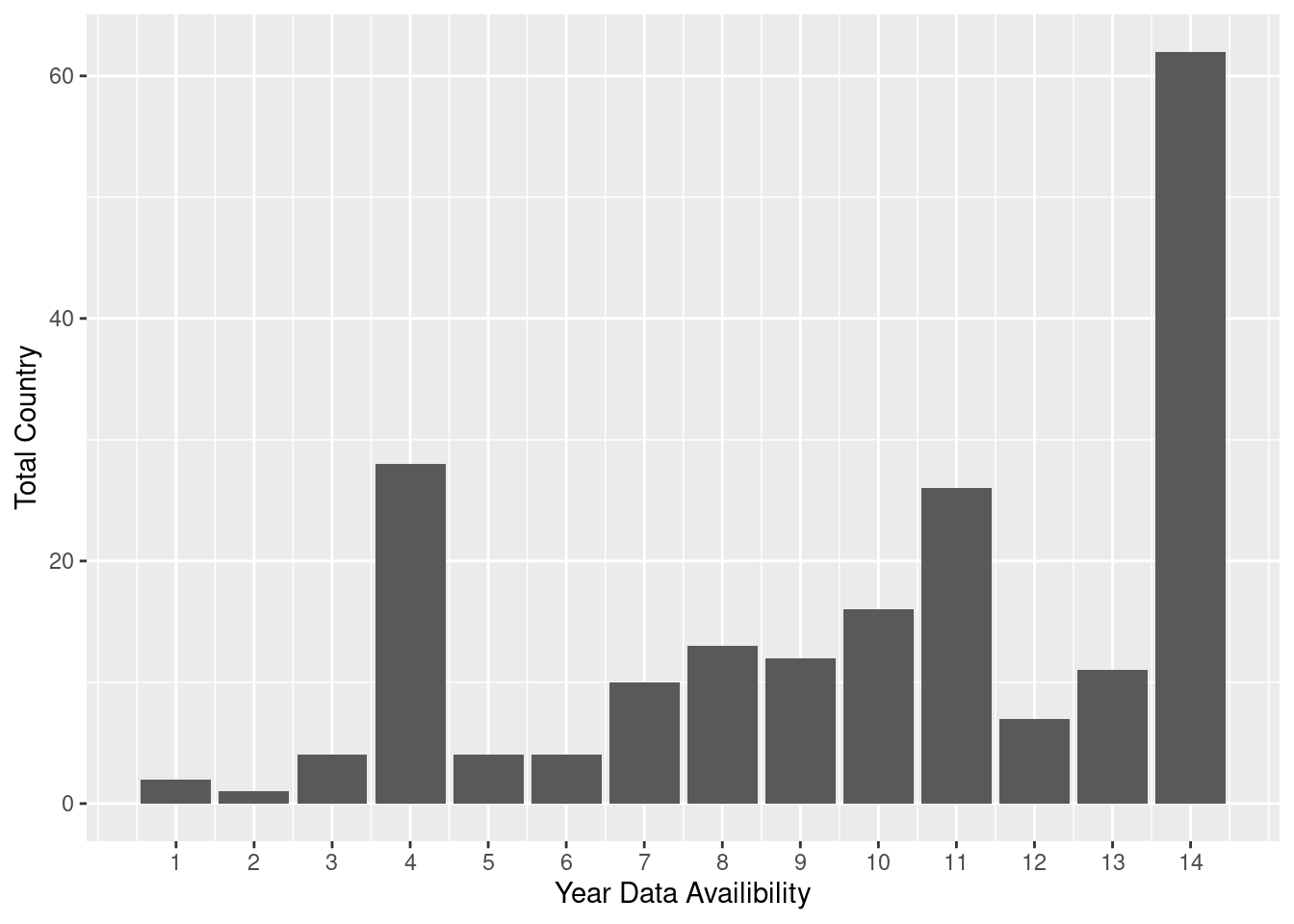
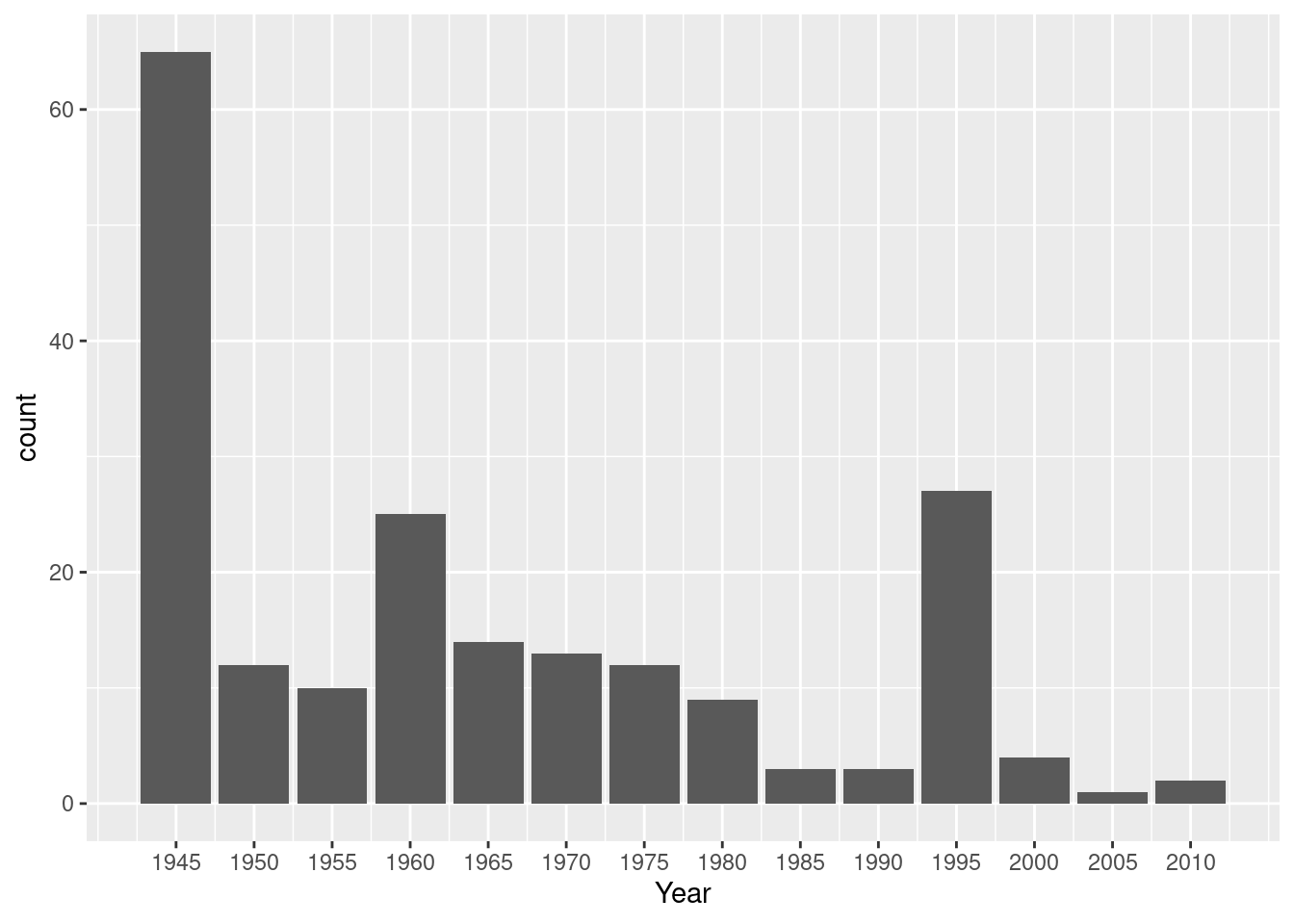
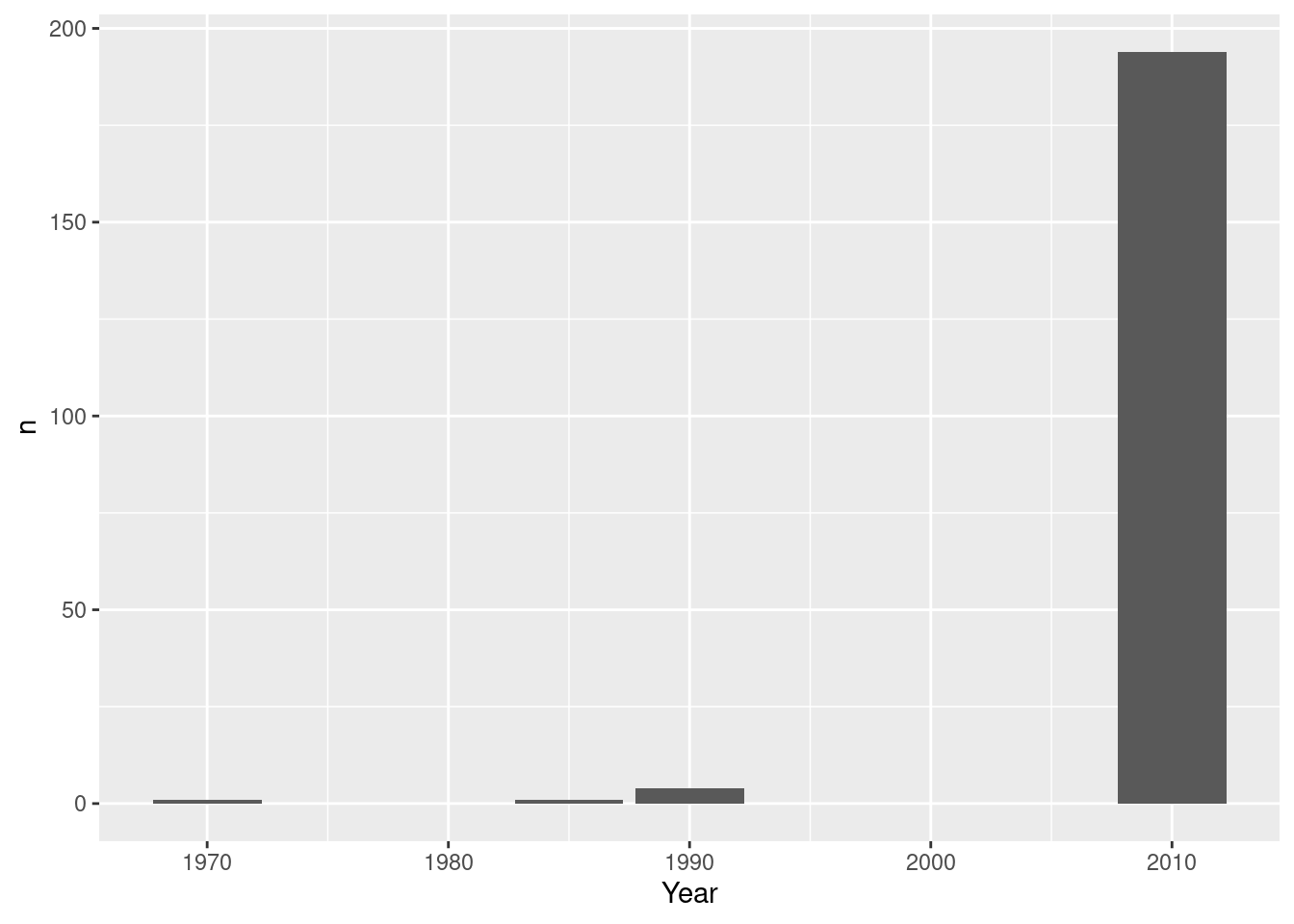
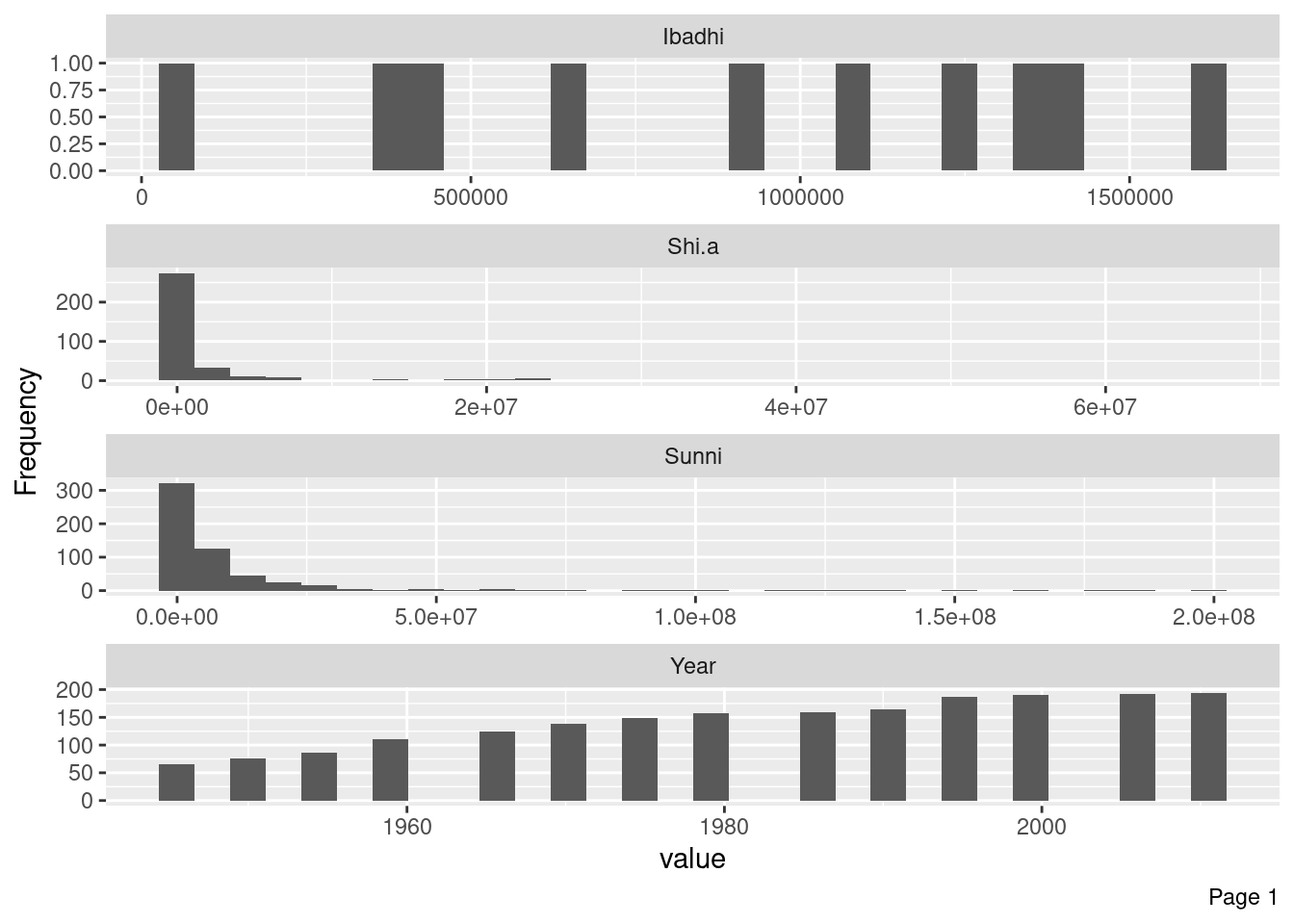
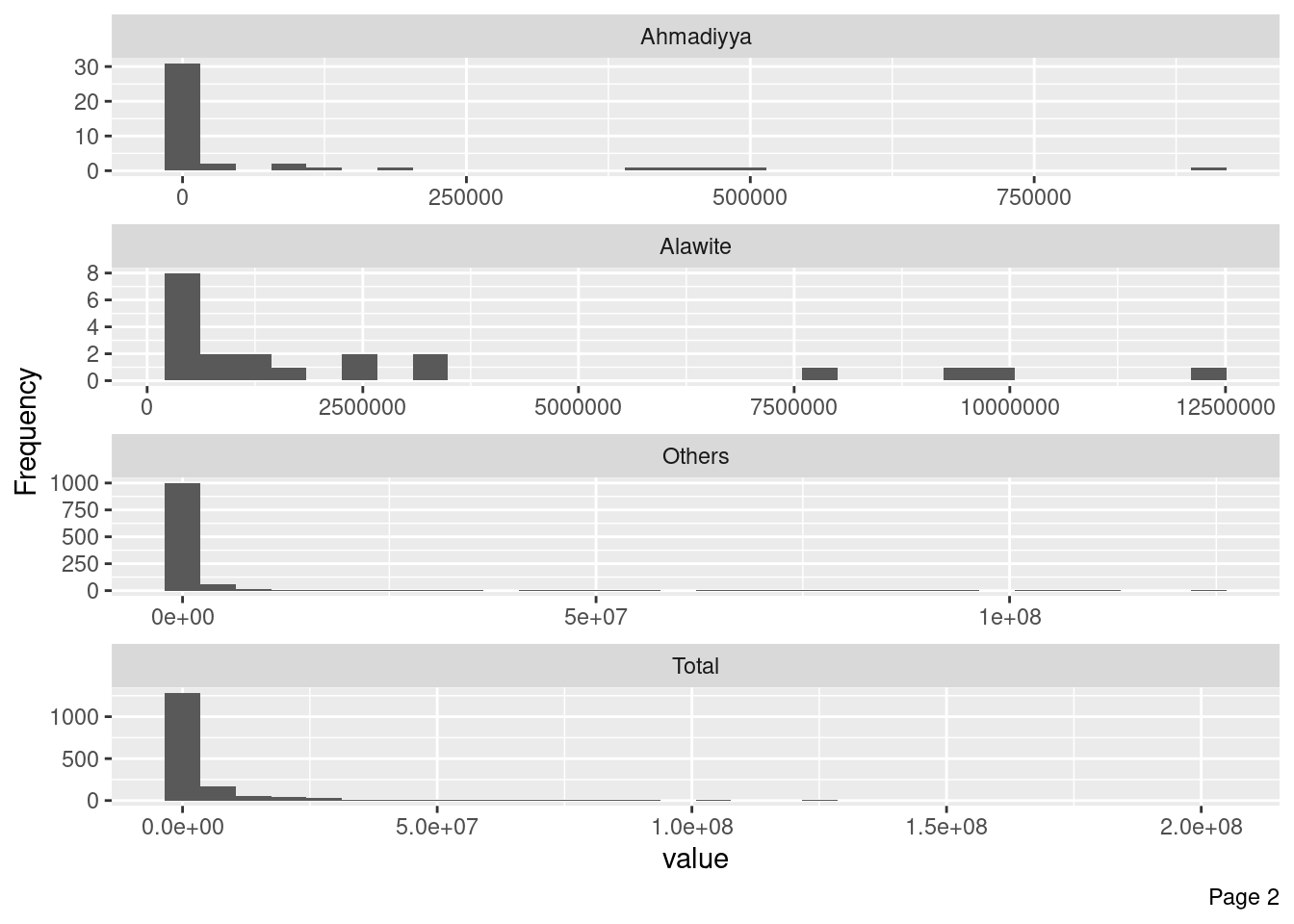
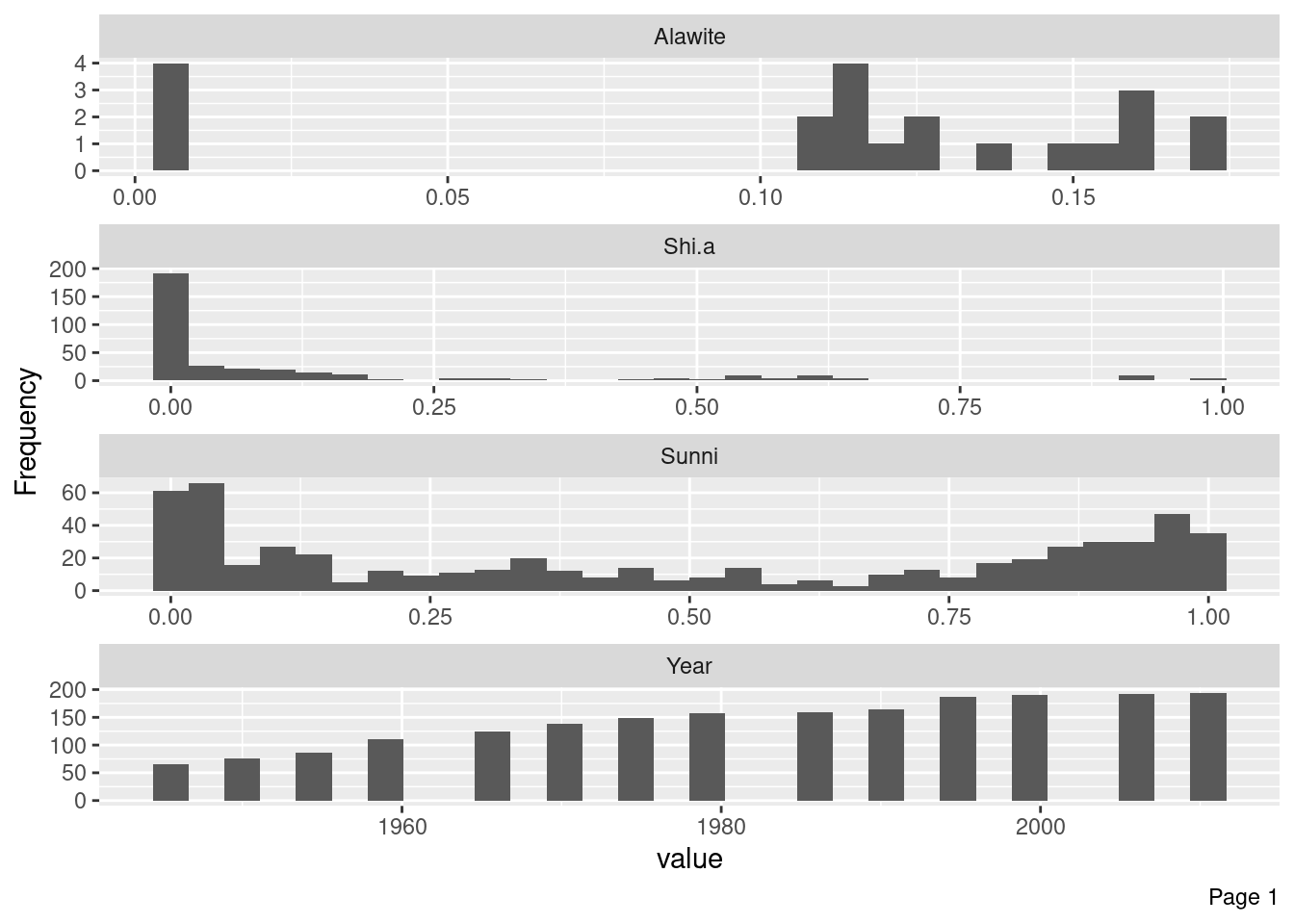
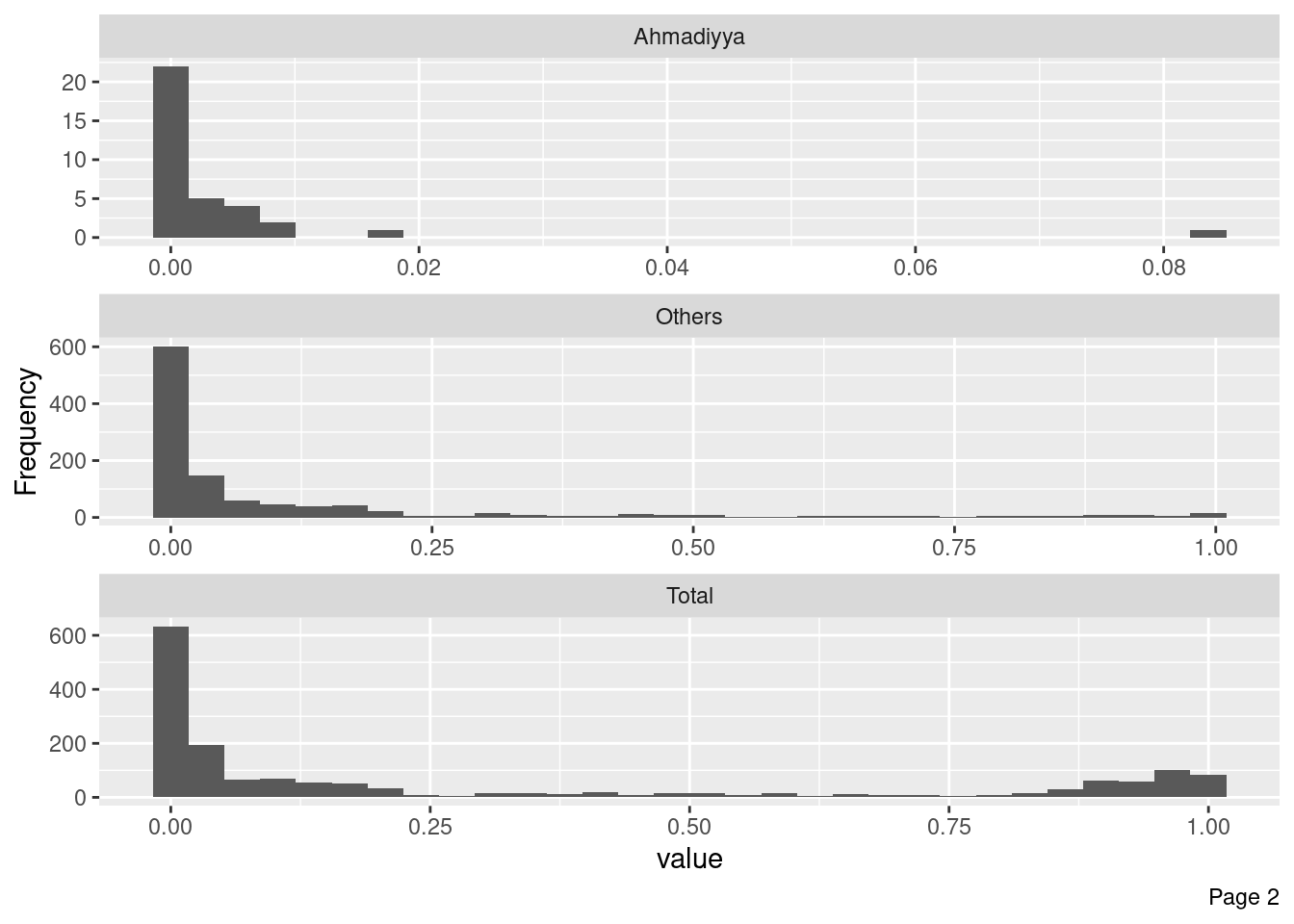
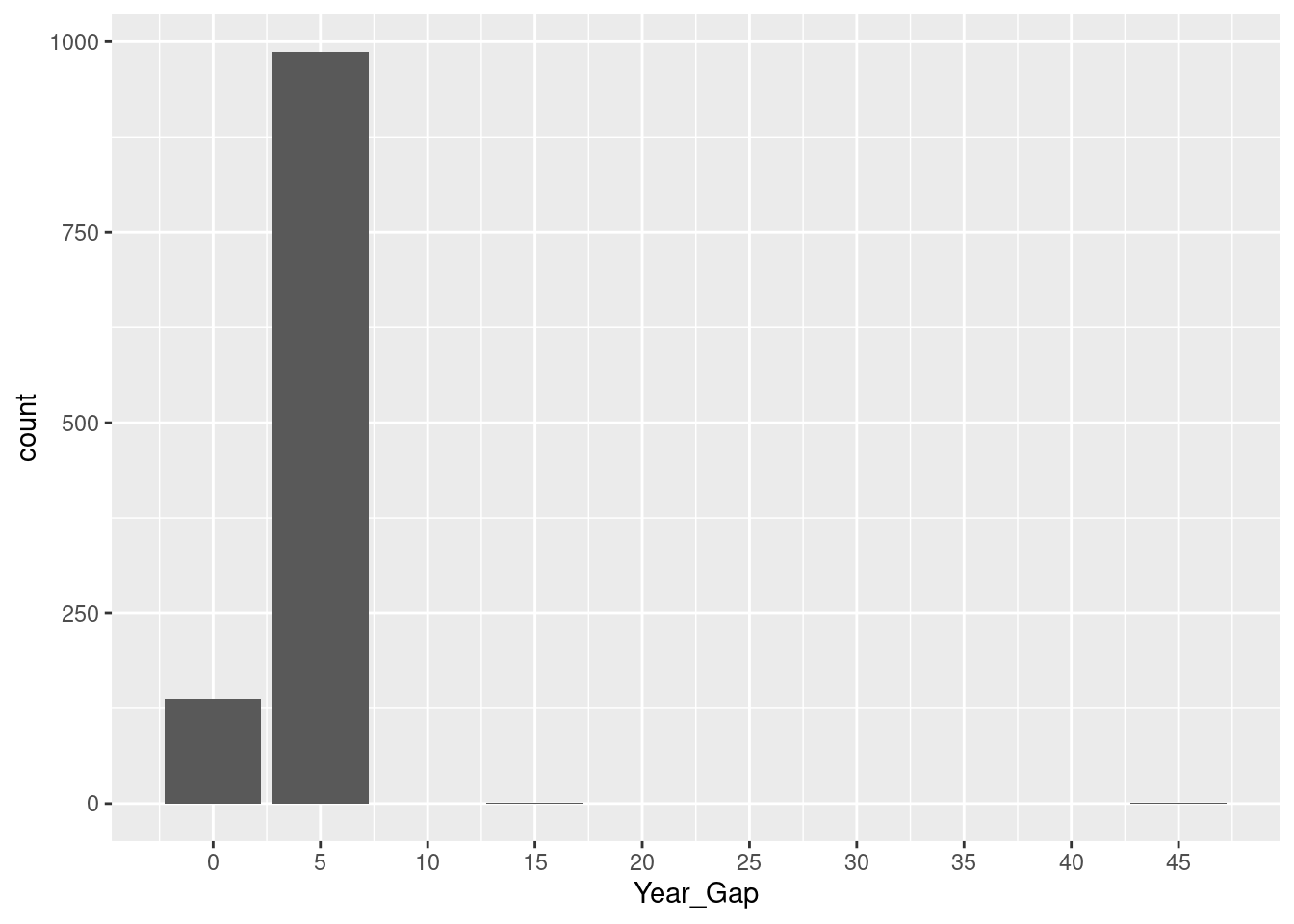# A tibble: 1,995 × 18
Country Year `Sunni (Population)` `Shi'a (Population)` `Ibadhi (Population)`
<fct> <dbl> <dbl> <dbl> <dbl>
1 United… 1945 NA NA NA
2 United… 1950 NA NA NA
3 United… 1955 NA NA NA
4 United… 1960 NA NA NA
5 United… 1965 NA NA NA
6 United… 1970 NA NA NA
7 United… 1975 NA NA NA
8 United… 1980 2407464 254121 NA
9 United… 1985 2186675 298183 NA
10 United… 1990 2019386 275371 NA
# ℹ 1,985 more rows
# ℹ 13 more variables: `Nation of Islam (Population)` <dbl>,
# `Alawite (Population)` <dbl>, `Ahmadiyya (Population)` <dbl>,
# `Others (Population)` <dbl>, `Total (Population)` <dbl>,
# `Sunni (Percent)` <dbl>, `Shi'a (Percent)` <dbl>, `Ibadhi (Percent)` <dbl>,
# `Nation of Islam (Percent)` <dbl>, `Alawite (Percent)` <dbl>,
# `Ahmadiyya (Percent)` <dbl>, `Others (Percent)` <dbl>, …